
Imagine having a superpower that helps you prepare for the unexpected. That's what synthetic data brings to machine learning. By generating artificial data that mimics real-world scenarios, you can tackle those rare and tricky edge cases that often trip up even the best models. This article is your go-to guide on how to harness the power of synthetic data to make your machine learning more robust, resilient, and ready for anything that comes its way.
Synthetic data is like a digital twin of real-world data, modeled after the patterns present in real datasets. It is created in the machine by using appropriate algorithms and models rather than collecting data directly from real-world events. This kind of data is especially helpful in cases where real data would be difficult to collect for reasons ranging from relatively high cost-to-scale and lack or scarcity of direct access to privacy issues and regulatory constraints.
There are several types of synthetic data, each with distinct characteristics and use cases:
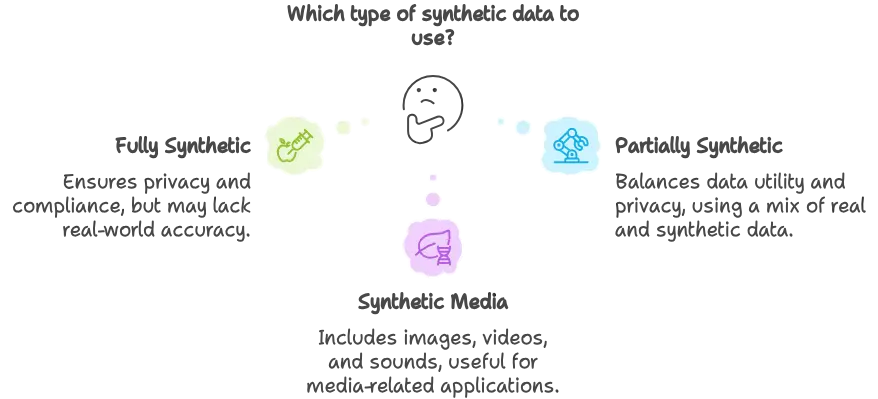
Common types of synthetic data used in machine learning applications
Edge cases are highly unusual scenarios that will almost certainly not be as adequately represented in standard datasets. These edge cases are what keep machine learning models robust and reliable—very important for critical applications such as autonomous driving or healthcare diagnostics.
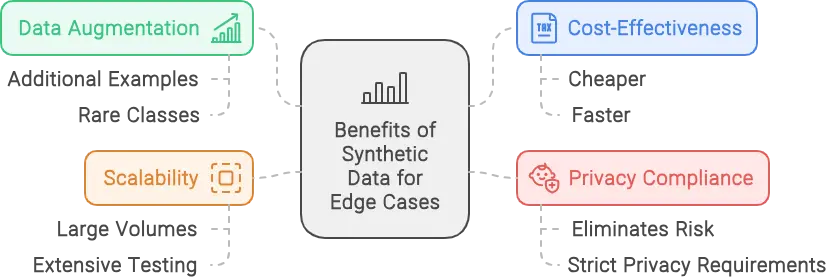
Key advantages of using synthetic data in machine learning workflows
| Generation Technique | Best For | Complexity | Edge Case Handling |
|---|---|---|---|
| Generative Adversarial Networks (GANs) | Image, video data | High | Excellent for diverse visual scenarios |
| Variational Autoencoders (VAEs) | Structured data, images | Medium | Good for controlled variation |
| Statistical Methods | Tabular data | Low | Limited but useful for simple cases |
| Simulation-Based Approaches | Physical systems, robotics | High | Excellent for physics-based edge cases |
"The true power of synthetic data lies in its ability to represent edge cases that real data collection might miss. This makes models more robust, safer, and ultimately more useful in real-world applications."
Dr. Sarah Reynolds, AI Research Scientist
Waymo, Google's self-driving car project, uses synthetic data to train its models on rare and dangerous scenarios. By generating synthetic data for edge cases like emergency vehicles, unusual road conditions, and rare weather phenomena, Waymo has been able to improve the safety and reliability of its autonomous driving systems without putting real vehicles or people at risk.
Researchers at Stanford University have used synthetic data to improve the accuracy of medical imaging models in detecting rare diseases. By generating synthetic images of uncommon conditions, they were able to train models that perform better on these edge cases while maintaining privacy and compliance with healthcare regulations.
Financial institutions use synthetic data to train fraud detection systems on unusual transaction patterns that might indicate fraud. By generating synthetic examples of various fraud scenarios, these institutions can enhance their models' ability to detect sophisticated fraud attempts without compromising sensitive customer data.
The most viable way of dealing with edge cases in machine learning is to use synthetic data. Synthetic testing using generated data can be a cost-effective, scalable, privacy-compliant solution for improving model robustness. By implementing appropriate synthetic data generation techniques, practitioners can enhance model training and ensure that rare critical scenarios are adequately covered.
As machine learning continues to be deployed in increasingly critical applications, the importance of handling edge cases correctly only grows. Synthetic data provides a powerful tool in this effort, allowing developers to create models that are not just accurate on average, but reliable even in the most unusual and challenging situations.
Synthetic data will only become more important as the field evolves, playing a crucial role in development, production, and archiving of machine learning models. Organizations that master the art of synthetic data generation will be better positioned to build AI systems that can handle the full complexity of the real world.
What's the difference between data augmentation and synthetic data generation?
Data augmentation typically involves making small modifications to existing real data (like rotating images or changing colors), while synthetic data generation creates entirely new data points from scratch using generative models or simulation.
How do I know if my synthetic data is realistic enough?
You can evaluate synthetic data quality through visual inspection (for images), statistical comparison with real data, and by measuring model performance when trained on synthetic versus real data. There are also specialized metrics like Fréchet Inception Distance (FID) for images.
Can synthetic data completely replace real data in machine learning?
For most applications, a hybrid approach is recommended. While synthetic data is excellent for augmenting datasets and covering edge cases, real data provides ground truth that's difficult to fully replicate. The best results typically come from combining both data sources.
How much synthetic data should I generate for edge cases?
This depends on your specific use case, but a general rule is to balance your dataset so that important edge cases are well-represented without overwhelming the common cases. For critical applications, you might want edge cases to comprise 10-30% of your training data.
Are there any industries where synthetic data is particularly valuable?
Synthetic data provides significant benefits in healthcare (for rare diseases), autonomous vehicles (for dangerous scenarios), finance (for fraud detection), and cybersecurity (for novel attack patterns)—essentially any field where edge cases are critical but difficult or expensive to collect naturally.

Your email address will not be published. Required fields are marked *
Loading questions...




